对USM文件的加密与解密研究
对USM文件研究的起因在于想要通过自行封装option的形式加载自制谱,但是没能找到USM文件的正向加密工具。几经辗转,最后找到了WannaCRI这个python库,支持USM与常见视频格式的双向转换,得以根据作者撰写的文档和库源码进行分析。下面以Maimai DX中的000000.dat文件为例,对USM文件进行分析。
USM文件结构
USM文件以块为单位进行存储,各个块以大端顺序存储,首尾相连合并成一整个USM文件。每个块又可分为块头和块体两个部分,其中块头固定8个字节,块体则不固定;块体内又分为载荷头、载荷和填充三个部分。这样的块结构在Criware的文件中非常常见。
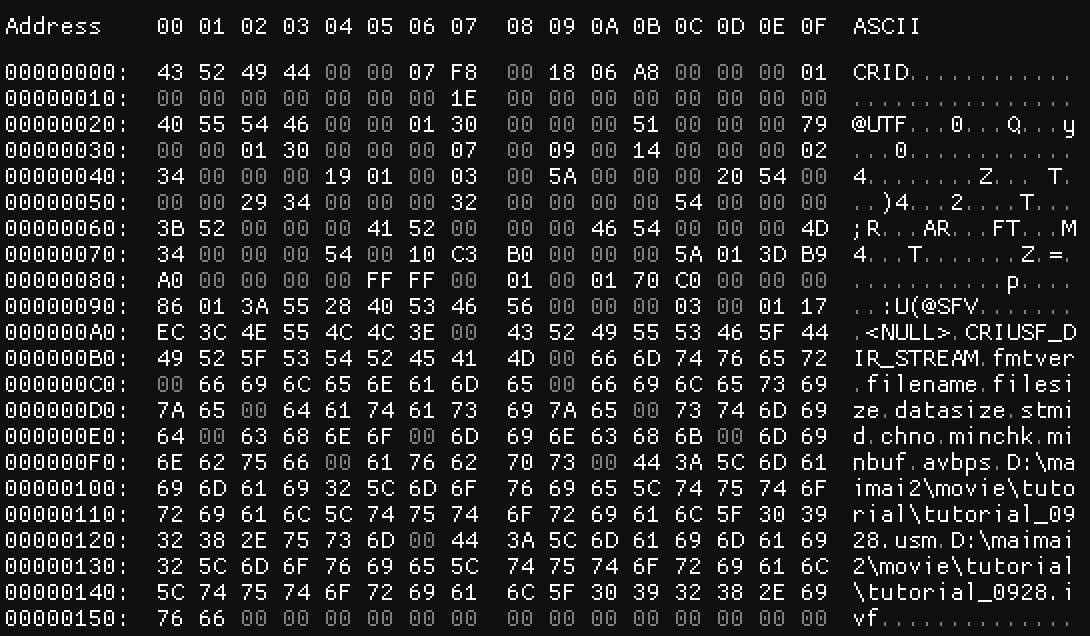
如图为000000.dat的前0x0015F字节,除此之外直到0x07FF均以0填充。
块头(8B)
块头为固定长度的8个字节,前4个字节为块标识符,标识了块的类型,后4个字节则标志了块的大小。
块标识符(4B)
块的类型有三种,CRID、@SFV和@SFA,以ASCII的形式记录。
- CRID:(
可能是CRIUSF_DIR的缩写?)每个USM文件只存在一个CRID块,且永远作为文件中的第一个块,其中存储了文件的元数据等信息; - @SFV和@SFA:
推测SF指的是Sofdec,V和A分别代表了视频和音频。这两种块的块体内包含的可以是数据帧,也可以是头或元数据。
Sofdec 2是Criware视频中间件真正的名字,CRI Movie 2似乎只是Criware在美国为Sofdec 2注册的商标。
块体大小(4B)
块大小以uint32_t的形式记录块体大小(即不含块头的剩余部分)。例如,000000.dat这一部分记录的数据为0x07F8,说明这个块的块体大小为2040B,即0x0005:0x07FF,符合文件中记录的情况。
块体(长度不定)
块体由载荷头、载荷和填充三部分组成。
载荷头(24B)
载荷头按照顺序可以分为以下部分
- 未知用途(1B)
- 载荷偏移(1B)
- 填充大小(2B)
- 通道编号(1B)
- 未知用途(2B)
- 载荷种类(1B)
- 帧时间(4B)
- 帧率(4B)
- 未知(8B)
载荷偏移(1B)
载荷偏移是指从块体的第一个字节到载荷第一个字节的偏移字节数。由于载荷头固定为24B,因此这个值始终为24,即0x18(参考000000.dat的0x0009)。
填充大小(2B)
从载荷结尾到块体结尾填充的字节数。例如,000000.dat的CRID块此处记录的数据为0x06A8,与实际填充结果相同。(所选区域前方的填充源于载荷内部,不属于填充的范围)
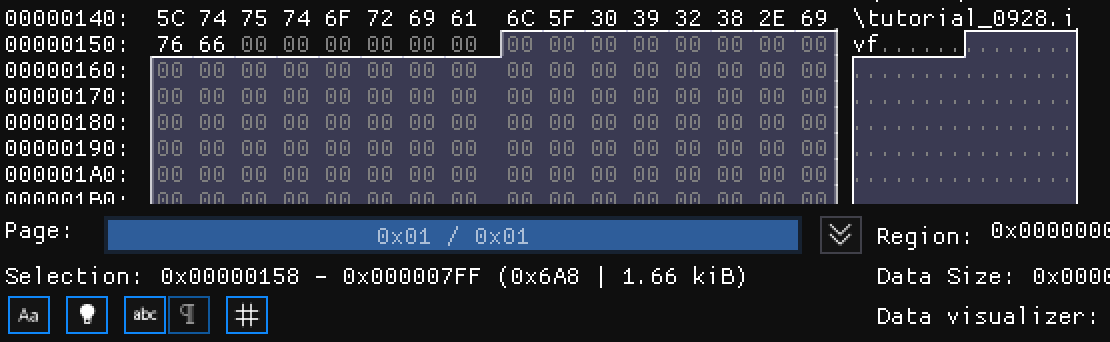
通道编号(1B)
指音频流或视频流所在的channel,是一个从0开始的uint8_t。CRID块的通道编号恒为0。
载荷种类(1B)
已知的载荷种类共有四种:
0x00stream:音视频流的二进制数据0x01header:音轨或视频轨的元数据等0x02section_end:标志着一个流、头、seek块或一系列数据块的结束0x03seek:标记了视频轨的查找位置
由此可以看出,000000.dat的载荷种类为header(位于0x000F)。
帧时间(4B)
用于同步音视频帧的时间码,数据类型为uint32_t。对于非媒体流的载荷,帧时间恒为0。
帧率(4B)
用uint32_t表示的帧率,其存储的数据为帧率的100倍,例如,30帧为3000(0x0BB8),29.97帧为2997(0x0BB5)。对于音频流,其存储的值恒为2997;对于非媒体流的载荷,其存储的值恒为30(0x001E)。
载荷
载荷可以为媒体流的原始数据,也可以是所谓的“字典载荷”。相关内容在下文展开介绍。
填充
由于USM格式是为CD设计开发的,为了保证扇区对齐,需要在数据结尾填充0x00以保证各个块都可以以更高的效率读取。(CRID块的大小似乎恒定为2048B?)
字典载荷(Dictionary Payloads)
尽管donmai将其称之为字典载荷,但我认为其结构更接近一个与csv类似的二维数组,下面我会以自己的理解来解释这一部分的内容,有关字典载荷的原始解释可以参考donmai的原始内容,这里我仍然会保持它的名称不变。
我们不妨先来看一段字典载荷的实例:

这是000000.dat的CRID块包含的载荷,可以非常明显的看到0-3字节的@UTF标识符以及4-7字节所代表的块体大小(0x0130,即304,说明块体长度为304B,范围从0x0028至0x0157)。
要理解接下来的内容,我们需要首先尝试理解这里存储了什么数据。假设我们突然灵光乍现,知道了这个载荷中存储的原始数据:
| fmtver: int | filename: str | filesize: int | datasize: int | stmid: int | chno: short | minchk: short | minbuf: int | avbps: int |
|---|---|---|---|---|---|---|---|---|
| 1936292453 | D:\maimai2\movie\tutorial\turorial_0928.usm | 20822432 | 0 | 0 | -1 | 1 | 94400 | 1098672 |
| 1936292453 | D:\maimai2\movie\tutorial\tutorial_0928.ivf | 20600104 | 0 | 1079199318(@SFV的字节编码) |
0 | 3 | 71660 | 1098672 |
可以看出,任何数据,包括标题行内的文本,都是合法的数据类型。尤其是字符串,非常好认,它们是直接以ASCII码的形式明文存储的,但对于其它数字类型,加密方式就要复杂一些。
正如前文所述,块头+(载荷头+载荷)+填充的形式非常常见,我们不妨假设这个名为@UTF的块头为8B(0x0020至0x0027),紧接着是24B的载荷头(0x0028至0x003F),之后则全部为载荷数据。我们不妨先来猜一猜这24B的载荷头包含了什么内容。载荷头的内容为
1
2
3
00 00 00 51 00 00 00 79
00 00 01 30 00 00 00 07
00 09 00 14 00 00 00 02
首先可以非常明显地看到00 00 01 30,即304,它与块体的长度完全一致,说明这可能是一个指向块末尾的指针,那么我们大胆假设一下,00 00 00 51和00 00 00 79同样代表了两个指针,那么他们究竟指向了哪里呢?
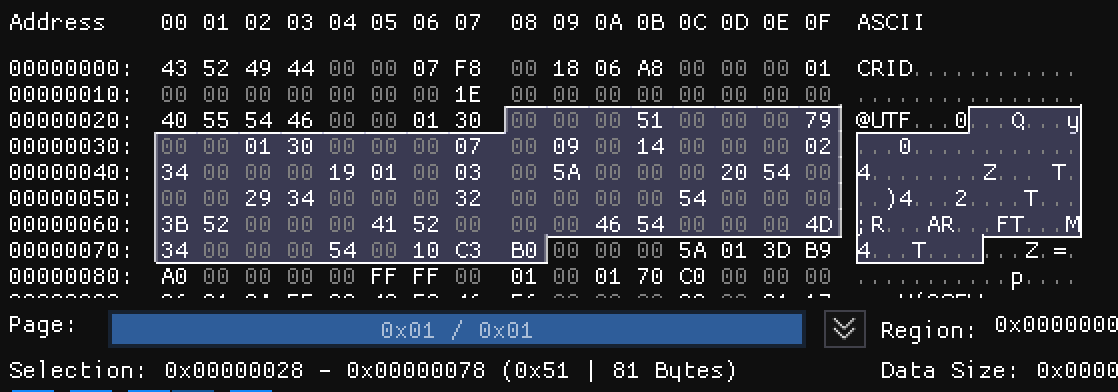
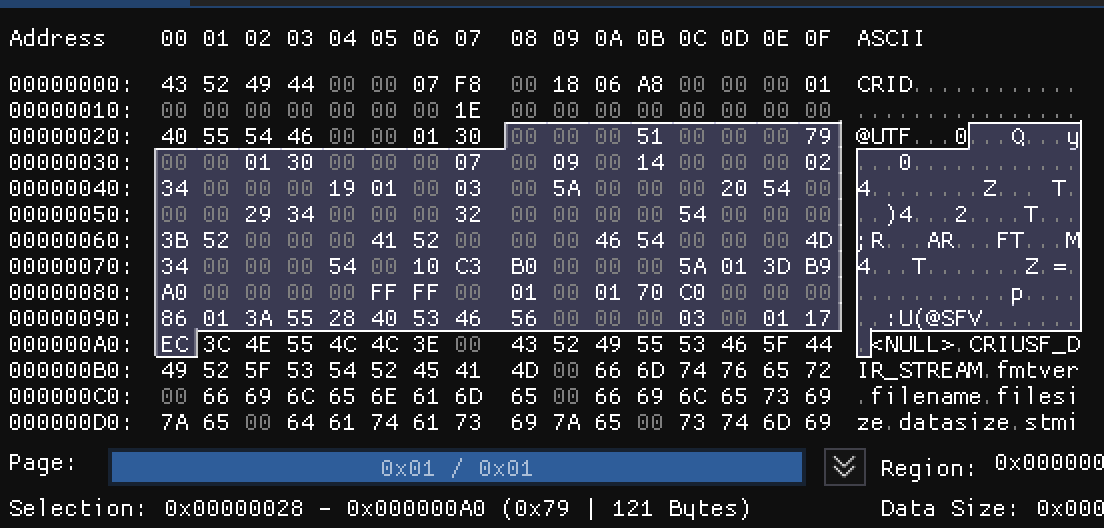
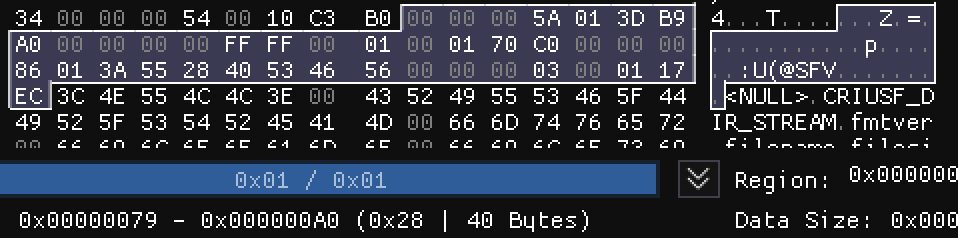
前者指向了一块未知区域,后者则指向了以ASCII存储的字符串所在的位置(注意图片下方Selection的所标识的大小,由于指针是从0开始的,所以高亮区域末尾的后一个字节才是对应指针所指的位置)。由此,整个载荷被拆分成了三个部分:第一部分:0x0040至0x0078,共57B;第二部分:0x0079至0x00A0,共40B;第三部分:0x00A1至0x0157,共183B。
事实上,字典载荷将原始数据划分成了四个部分:数据I、数据II、字符串数据、字节流数据。其中,后三个部分均为数据I的拓展。除了数据I位于载荷头后方不需要指针外,三个指针分别指向了剩下的三个部分(由于示例中不存在字节流数据,因此指针被指向了载荷的结尾)。
数据I
这部分数据的每一个部分都以标志位(1B)+数据标题指针(4B)+本地数据(不定)的格式构成,每个部分都代表了数据表中的一个单元格,并依次首尾相接。下面以上述出现的数据I中的第一组数据,34 00 00 19 01 00 03 00为例,介绍这三个部分。
标志位
标志位由两部分构成,分别是数据类型和启用数据II标志。如果需要启用数据II,那么这一格的数据将存储在数据II中,反之则存储在数据I的本地数据部分中。标志位的数据类型使用字节中的低5位存储,与数据类型对应的关系具体如下表。启用数据II使用第6位和第7位标识,如果不启用数据II,则将第6位置1,第7位置0(00100000b);启用数据II,则将第7位置1,第6位置0(01000000b)。例如,上述数据的第一个字节为0x34,即00110100b,说明这里存储的是一个int类型的值,且没有启用数据II。
| 数据类型 | 标志 | 长度/Byte |
|---|---|---|
| Char | 10000b | 1 |
| Unsigned char | 10001b | 1 |
| Short | 10010b | 2 |
| Unsigned short | 10011b | 2 |
| Integer | 10100b | 4 |
| Unsigned Integer | 10101b | 4 |
| Long long | 10110b | 8 |
| Unsigned long long | 10111b | 8 |
| Float | 11000b | 4 |
| Double | 11001b | 8 |
| String | 11010b | 头指针为4B,指向字符串数据 |
| Bytes | 11011b | 头指针与尾指针各4B,指向字节流数据 |
数据标题指针
这一部分为固定4B长度,是一个用于字符串数据部分的指针,指向这个数据标题位于字符串数据的开头。例如,上述例子中的00 00 00 19在字符串数据中指向的是fmtver,说明这个数据的标题是fmtver(formet version)。

本地数据
未启用数据II时直接存储在数据I中的数据,如果启用了数据II,这一部分则不存在。存储在数据I中的数据意味着每一行的相应数据都会从本地数据中复制。
例如,上述例子中,标志位指示这里存储的数据是长度为4B的int类型,且直接存储在数据I中,因此继续向后读4B,数据为01 00 03 00,直接转换成int为1936292453。(虽然我更倾向于认为它想表达的意思是Ver.1.03.00)
数据II
这里用于存储数据I中没能存储的数据,它们没有指针和标志位,完全按序排放。例如,若数据I中的第3部分为54 00 00 00 29 34,其中的0x54即为01010100,0x29对应的数据标题是filesize,说明这是一个存储在数据II中的int类型数据,代表了文件的大小。由于它是第2个存储在数据II中的数据,因此读取数据II的4-7字节,得到01 3D B9 A0,即20822432。我们对000000.dat这个文件的大小进行检查,发现结果完全一致。

字符串数据
字符串数据以<NULL>开头,各个字符串之间用0x00隔开。例如:
1
<NULL>\x00CRIUSF_DIR_STREAM\x00fmtver\x00filename\x00filesize\x00datasize\x00stmid\x00chno\x00minchk\x00minbuf\x00avbps\x00D:\maimai2\movie\tutorial\tutorial_0928.usm\x00D:\maimai2\movie\tutorial\tutorial_0928.ivf
载荷头
在分析完载荷后,我们再回过头来重新分析载荷头。仍然以上述CRID块中的数据为例。

载荷头共24字节,按顺序分别是:
- 数据II偏移(4B):记录了数据II的起始位置。示例中为
0x000051。 - 字符串偏移(4B):记录了字符串数据的起始位置。示例中为
0x000079。 - 字节流偏移(4B):记录了字节流数据的起始位置。示例中为
0x000130,与载荷大小相同,故该区块不存在。 - 载荷名偏移(4B):记录了当前字典载荷名称在字符串数据中的起始位置。例如,上述载荷中载荷名偏移为
0x000007,在字节流数据中查找得知这个载荷的名称为CRIUSF_DIR_STREAM;

- 元素个数(2B):数据表中每一行的元素个数。示例中为
0x0009,即每一行都有9个元素; - 每行数据所需数据II大小(2B):每一行数据所使用数据II的大小。示例中为
0x0014,由于示例有2行数据,因此数据II总共占据0x0028。
- 行数(4B):记录了总共有多少行数据。示例中为
0x0002,即2行。